你的AI正在“裸奔”吗?全球5万Ollama实例暴露公网风险解析
Ollama 因其简单易用而备受欢迎,但这背后隐藏着巨大的安全隐患。数以万计的 Ollama 实例正毫无防备地暴露在公网上,任何人都可以滥用其计算资源,甚至控制服务器。本文通过真实的网络测绘数据,揭示了这一问题的严重性,深入分析了其危害,并提供了立即可行的防护指南。
Intro
提到本地大语言模型(LLM)部署,很多人都知道Ollama。尽管对比其他框架(vllm, sglang, lmdeploy等)其性能并不出众,,但是因其简便的上手体验而广受欢迎。
然而,对于追求精细控制和专业部署的用户而言,它在某些方面显得不够成熟,因为很多参数根本就不明朗,调整困难,其中包括:
- 上下文窗口大小不透明且难以设置。
ollama pull拉取的模型格式特殊,其他推理引擎通常无法直接使用。
Terrible model management for external use
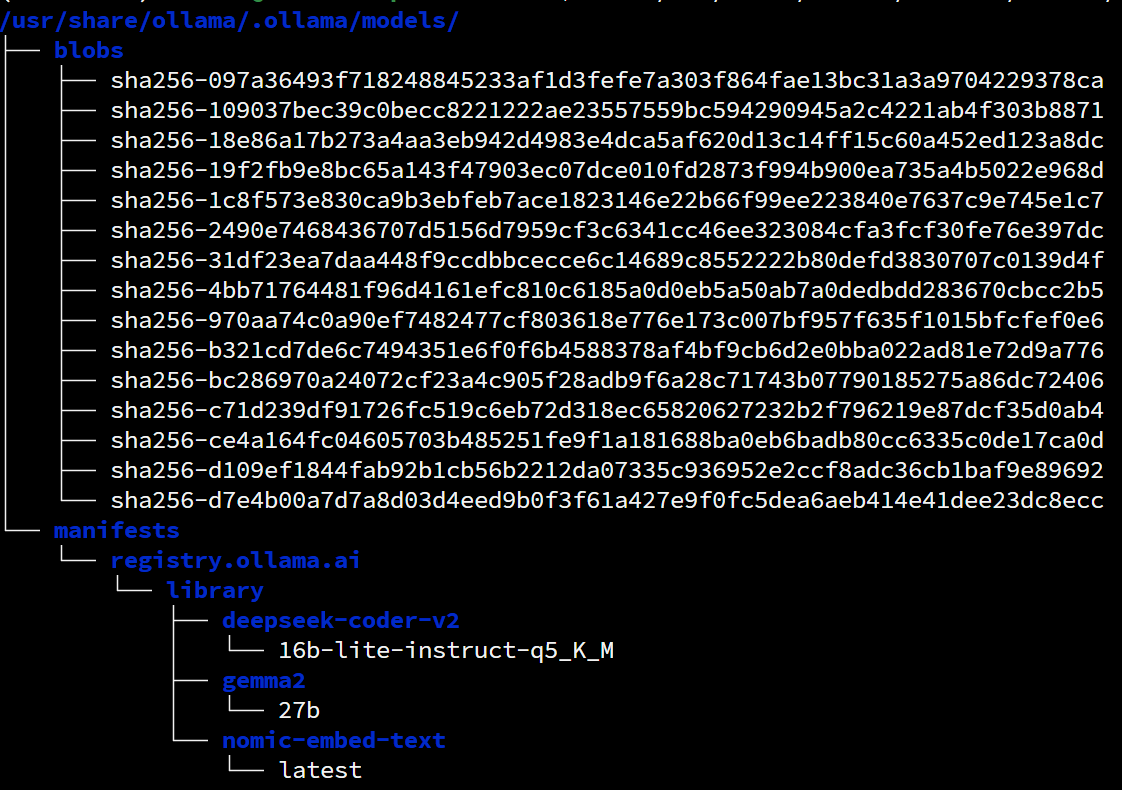
相比较,同样是 llama.cpp 后端的 LM Studio 在模型管理上则更为清晰:
如果说上面这些还只是小问题,那么在多GPU服务器上使用 Ollama 更像是一场灾难——你无法直接指定运行的GPU,甚至连 CUDA_VISIBLE_DEVICES 环境变量都不起作用,除非你能找到一些“奇技淫巧”1。
当然,本文的重点并非上述问题,而是 Ollama API 暴露在公网时的严重安全风险。早在一年前,就有人通过网络空间搜索引擎发现,全球存在大量运行着 Ollama 实例且毫无防护的服务器。
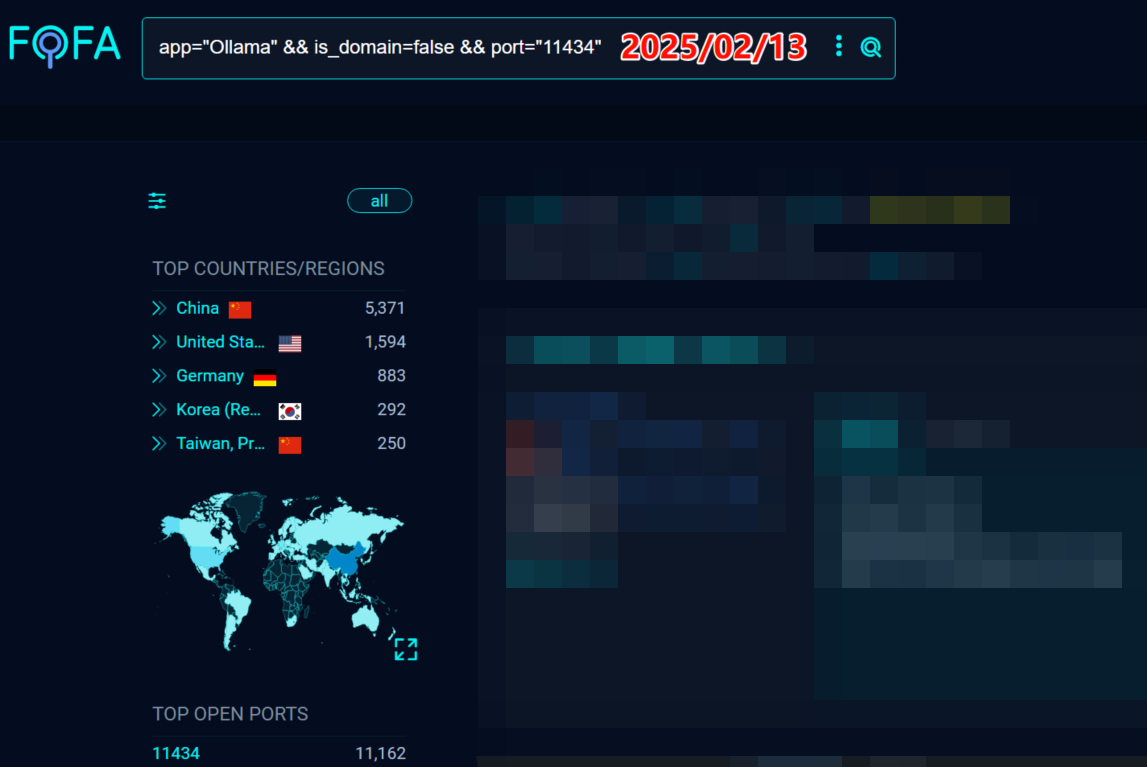
我在2025年2月首次关注到这个问题,当时全球约有近10000个暴露在公网的 Ollama 服务器。
而到了撰写本文的2025年10月,这个数字飙升到了近50000个。
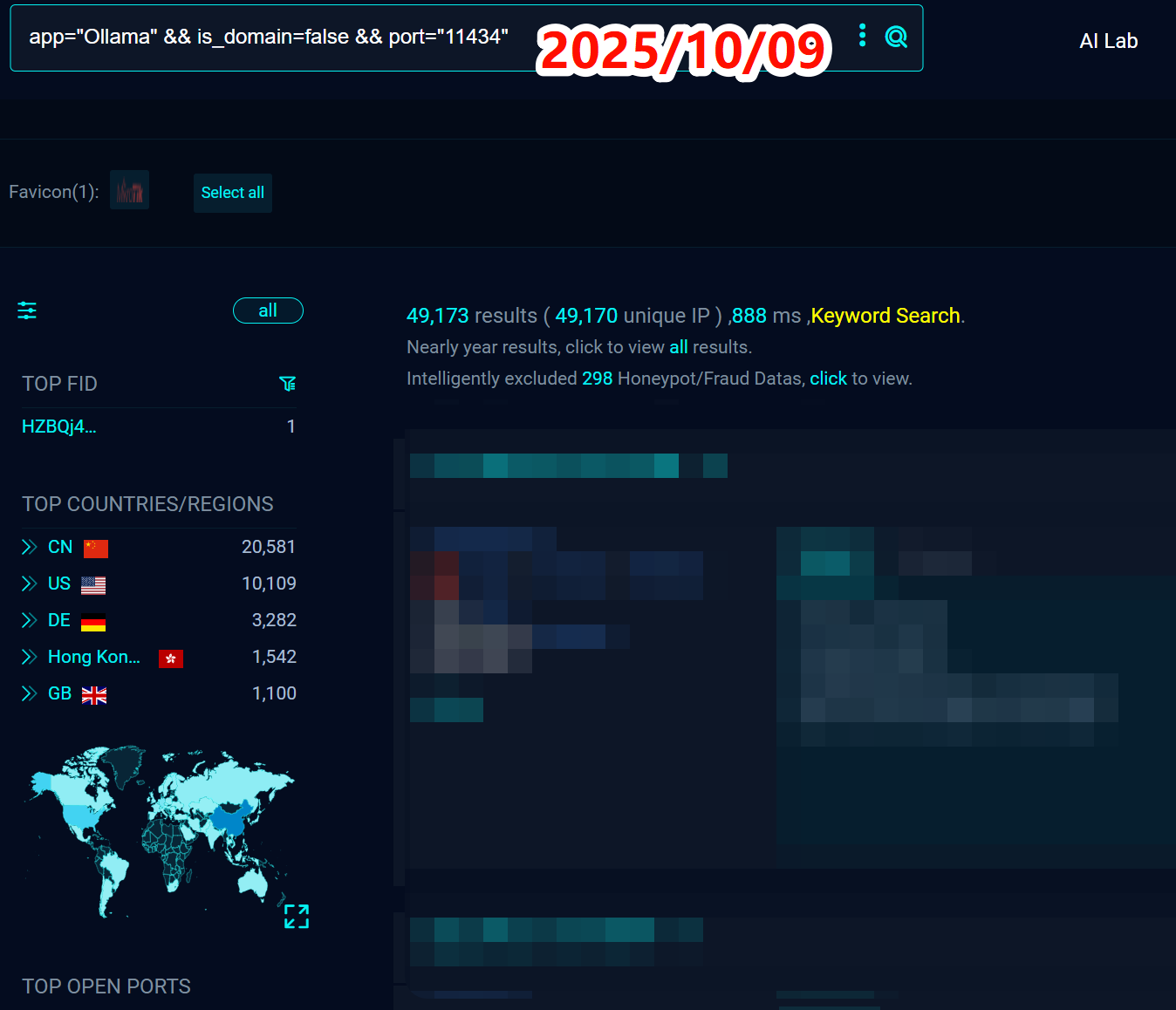
最令人担忧的是,时间过去了8个月,这些服务器中的绝大部分依然没有任何身份验证机制,任何人都可以随意访问。
为什么会出现这样的情况
首先,Ollama 默认只监听 127.0.0.12,这本身是安全的。用户需要查阅 文档 或者类似的 issue ,修改系统服务配置并重启,才能让它监听公网地址 0.0.0.0。
虽然配置过程不算简单,但许多用户为了方便远程调用,依然选择了将其完全暴露。这些用户可能缺乏足够的网络安全知识,加上 Ollama 简单上手、深受小白喜爱的特性,共同导致了今天庞大的裸奔实例数量。
其次,也是最关键的一点:Ollama 在监听到 0.0.0.0 时,没有任何强制性的身份验证或风险警告。这种“沉默的许可”无疑助长了不安全配置的蔓延,短短8个月内,暴露实例的数量就翻了五倍。
最后一个重要原因是 Ollama 的架构设计。与其他纯粹执行推理任务的框架(如 vllm)不同,Ollama 在后台运行一个系统级的守护进程。这个守护进程使得 Ollama 能随时响应 API 请求,按需下载或加载模型。模型在闲置约5分钟后会被卸载以释放资源。这种“永远在线”的便利设计,一旦暴露在公网,就意味着攻击者可以随时唤醒服务,执行任意模型操作,使其危险性倍增。
时至今日,在官方的 GitHub 仓库中,关于添加原生鉴权功能的 issue 仍在不断被提出3。
危害
暴露一个未经保护的 Ollama API,无异于将你服务器的钥匙交到陌生人手中。其危害可以分为三个层级:
危害一:计算资源滥用与财务损失
这是最直接的后果。攻击者可以无限制地调用计算密集型API(POST /api/chat, /api/generate, /api/embeddings),盗用你的 GPU/CPU 资源为他们服务,例如进行大规模文本生成、数据清洗或训练任务。
这不仅会导致你的服务器持续高负载,正常服务响应缓慢,甚至可能因云服务商的高额账单而造成巨大的财务损失,最终形成事实上的拒绝服务攻击4。
危害二:数据与模型完整性被破坏
攻击者不仅能“使用”你的服务,还能“管理”你的模型资产,随意破坏你的数据和模型完整性。
- 获取模型列表: 攻击者可以轻易获取你服务器上所有的模型及其详细信息。
curl http://ip:11434/api/tags

- 下载任意模型: 攻击者可以通过
pullAPI 下载任意模型到你的服务器。
curl http://ip:11434/api/pull -d '{
"model":"qwen3:0.6b"
}'
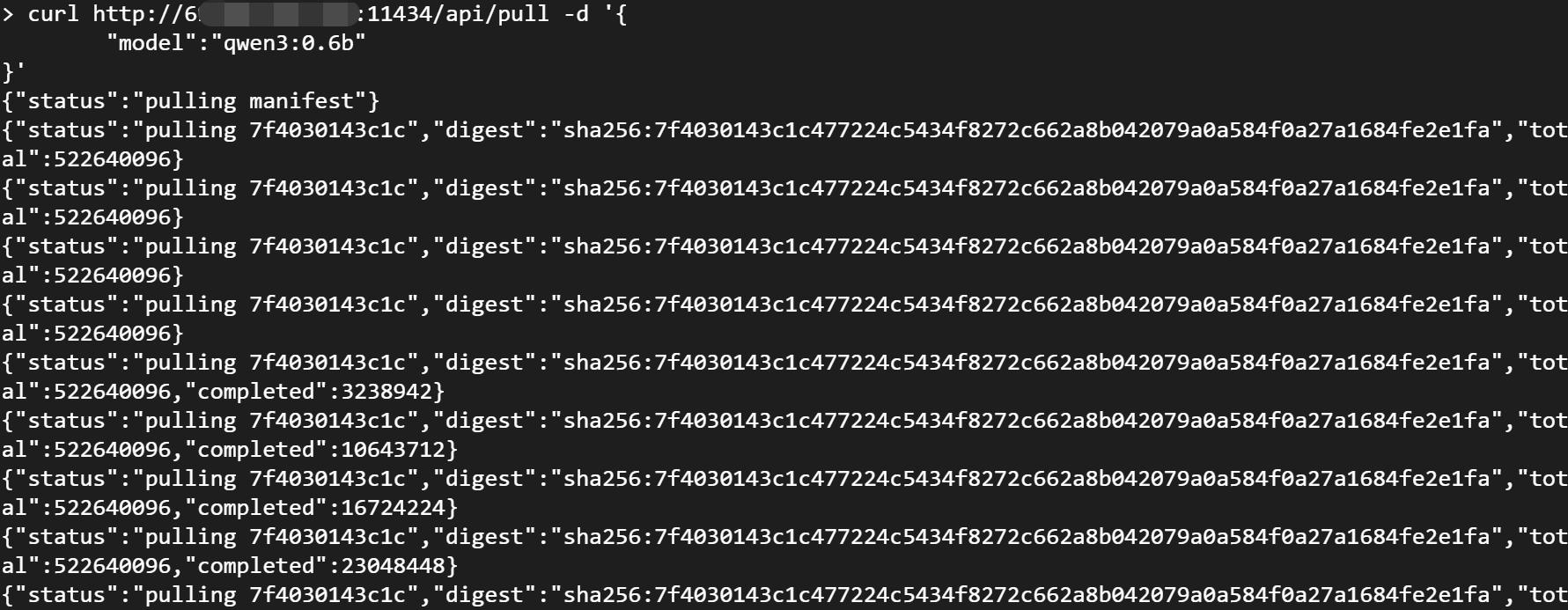
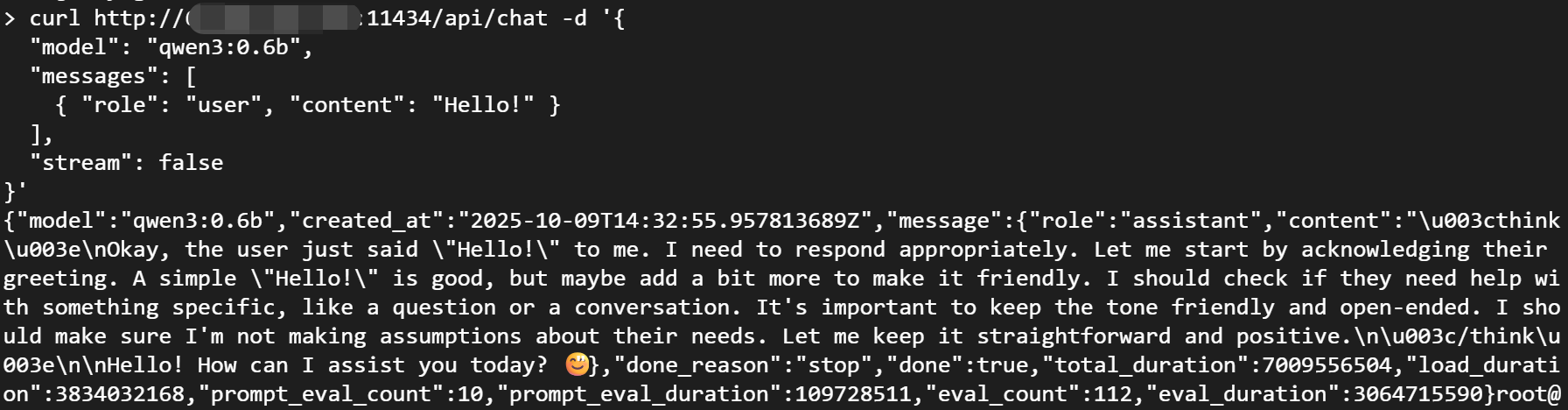
- 运行任意模型:攻击者可以轻易运行你服务器上所有的模型
curl http://ip:11434/api/chat -d '{
"model": "qwen3:0.6b",
"messages": [
{ "role": "user", "content": "Hello!" }
],
"stream": false
}'
- 删除任意模型: 攻击者也可以删除你服务器上已有的任意模型,包括你自己的私有模型。
curl -X DELETE http://ip:11434/api/delete -d '{
"name": "qwen3:0.6b"
}'


以及一大堆其他(可能更加危险)的功能,例如创建(create)、复制(copy)、推送(push)模型等更高权限的操作,都可以通过这个Ollama API 完成。
危害三:服务器安全与系统入侵
这是最严重、最危险的后果。完整的 API 权限意味着攻击者拥有了入侵你服务器的潜在跳板。
- 存储空间耗尽攻击: 攻击者可以编写脚本循环调用
pullAPI,不断下载llama3:70b这类超大模型,在短时间内迅速耗尽你服务器的硬盘空间,导致系统崩溃。 - 信息泄露: 如果你正在测试或使用私有模型,攻击者可以下载并窃取这些模型文件,或通过
showAPI 获取其配置细节,造成商业或研究机密泄露。 - (潜在的)任意代码执行:
POST /api/create接口允许通过Modelfile创建新模型。虽然 Ollama 有一定的沙箱机制,但高级攻击者可能利用此功能,或结合模型自身的漏洞,诱导系统执行恶意指令,最终完全控制你的服务器。
如何防范
那么,我们该如何保护自己的 Ollama 服务,防止其被他人滥用呢?
黄金法则:永远不要在没有安全措施的情况下,将 Ollama 直接暴露在公网上。
最基础也是最重要的一步,是确保 Ollama 服务只监听本地回环地址 127.0.0.1,而不是 0.0.0.0。这样可以保证只有服务器本机才能访问到它,从源头上杜绝了外部访问的可能。
如果你确实需要远程访问,请务必从以下几种方案中选择一种或多种进行部署:
- 使用防火墙: 配置防火墙规则(如
iptables,ufw),只允许来自特定可信 IP 地址(例如你的办公室或家庭网络 IP)的访问。 - 使用反向代理添加鉴权5: 在 Ollama 前面部署一个反向代理服务器,如 Nginx, Caddy 或 Traefik。在反向代理层配置身份验证,例如:HTTP Basic Auth。
- 使用 VPN 或隧道: 将你的服务器和客户端设备加入一个虚拟专用网络(如 WireGuard, Tailscale),这样你就可以通过一个安全的私有网络地址访问 Ollama,而无需将其暴露在公网上。
我们作为用户只能做这些防止自己的资源被滥用,希望这篇文章能让更多人意识到风险的严重性,并立即行动起来。
但更重要的是,希望 Ollama 官方能够正视这一普遍存在的安全隐患,尽快在产品中内置原生的身份验证功能,或在用户首次启动服务时,以醒目的方式提示公网暴露的巨大风险,将用户的安全置于更优先的位置。