Is Your AI Running Naked? Analyzing the Risk of 50,000 Exposed Ollama Instances
Ollama’s simplicity has made it popular for local LLMs, but it hides a critical security flaw. Tens of thousands of Ollama instances are exposed to the public internet without authentication, allowing anyone to hijack GPU resources and even compromise the server. This article uses real-world data to reveal the scale of the problem, details the severe risks, and provides essential steps to secure your instance immediately.
Introduction
When it comes to deploying local Large Language Models (LLMs), Ollama is a name many recognize. Although its performance isn’t as outstanding as other frameworks (like vllm, sglang, lmdeploy, etc.), it is widely popular for its simple onboarding experience.
However, for users who seek fine-grained control and professional deployment, it appears immature in some aspects, exposing several notable design flaws:
- The context window size is opaque and difficult to configure.
- Model files pulled via ollama pull are in a special format that other inference engines typically cannot use directly.

Terrible model management for external use
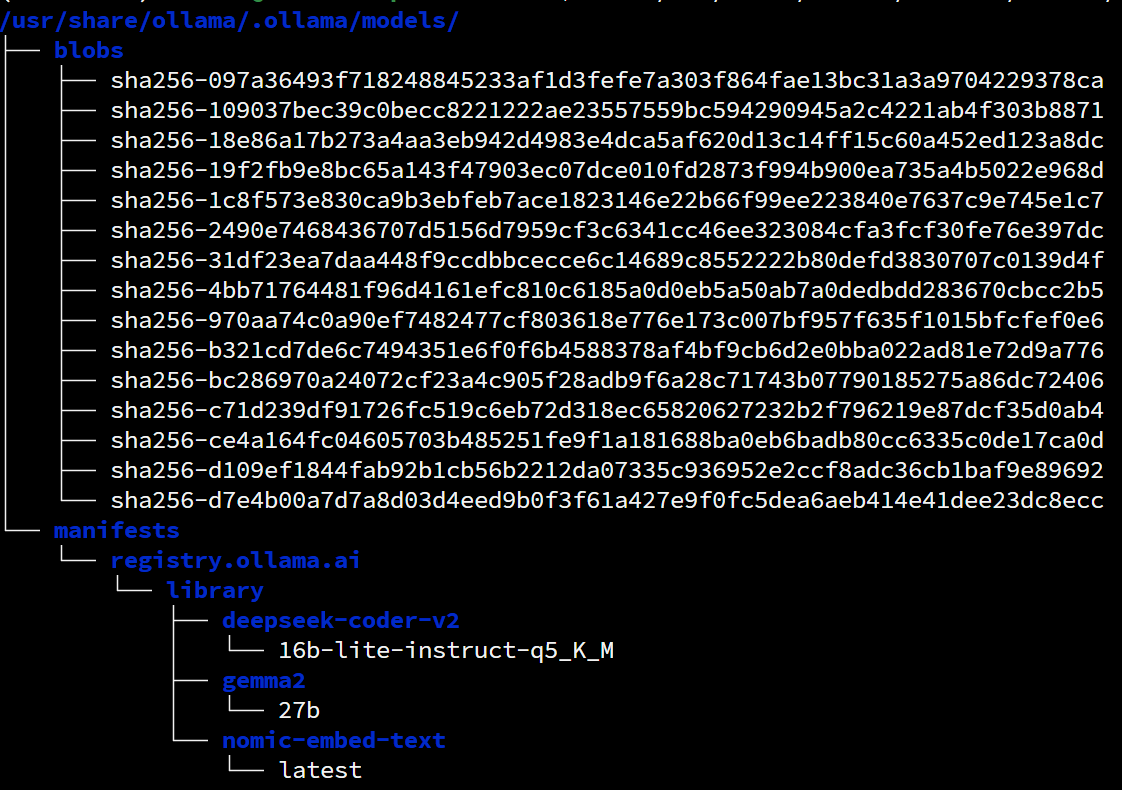
In comparison, LM Studio, which also uses a llama.cpp backend, offers a more clear approach to model management:
If the above are minor issues, using Ollama on a multi-GPU server is even more of a disaster—you cannot directly specify which GPU to run on, and even the CUDA_VISIBLE_DEVICES environment variable doesn’t work, unless you can find some clever workarounds1.
Of course, the focus of this article is not the issues mentioned above, but the critical security risks of exposing Ollama’s API to the public internet. As early as a year ago, people pointed out that a simple search on internet-wide scanners could reveal a large number of servers running unprotected Ollama instances.
I first noticed this issue in February 2025, when there were nearly 10,000 Ollama servers exposed online.
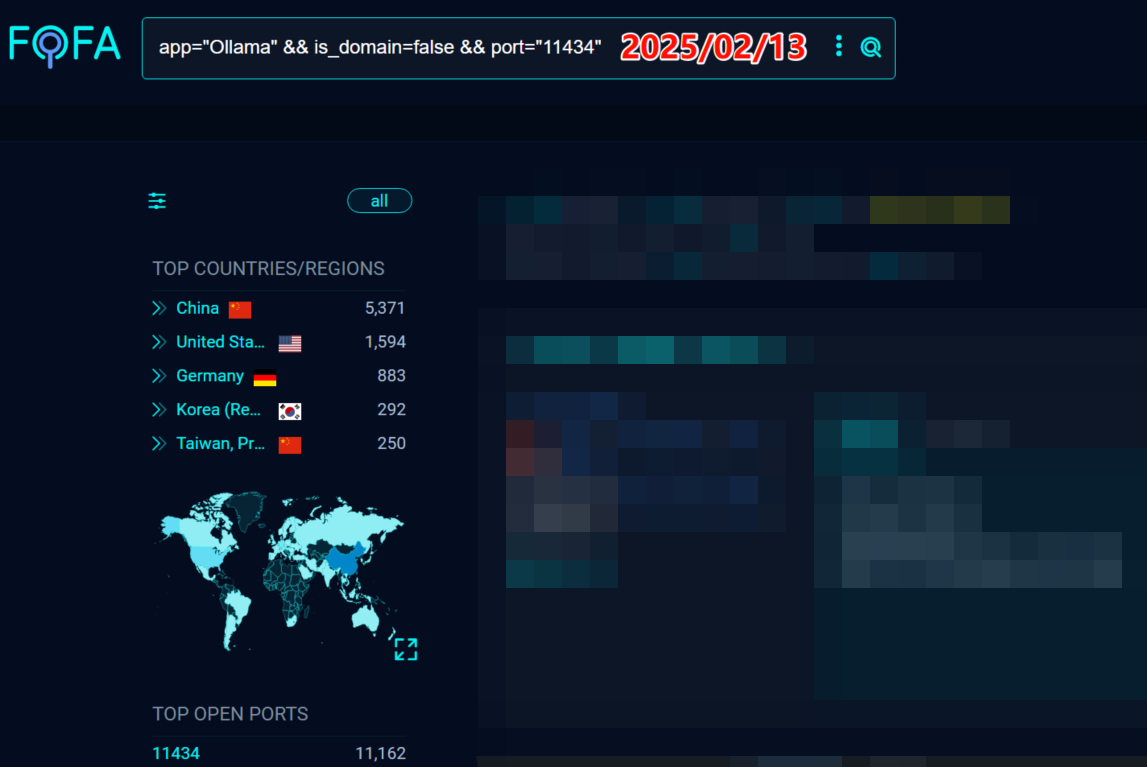
By the time of this writing in October 2025, that number has skyrocketed to nearly 50,000.
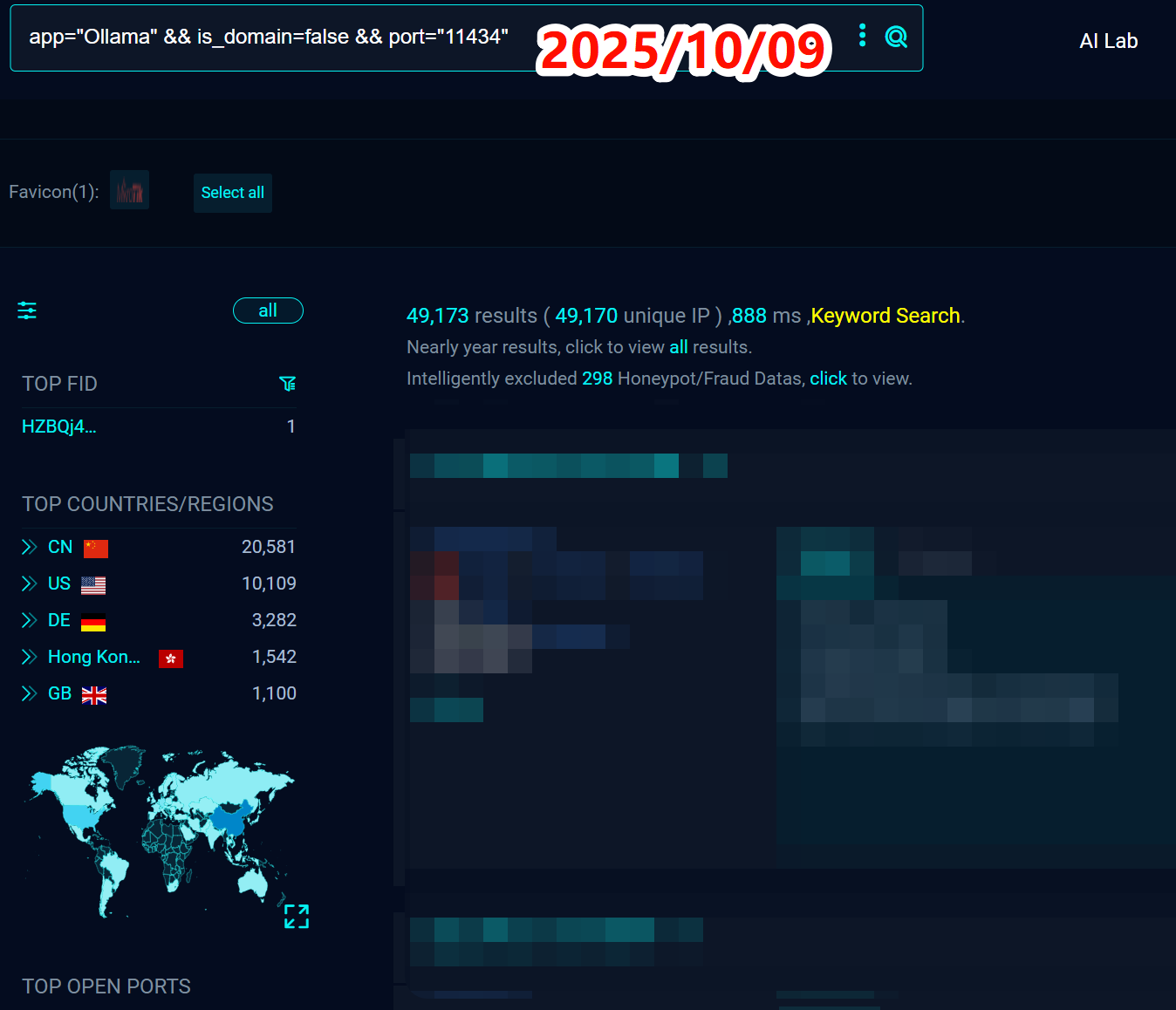
Most alarmingly, eight months have passed, and the vast majority of these servers still lack any authentication mechanism, allowing anyone to access them freely.
Why Is This Happening?
First, Ollama is secure by default, listening only on 127.0.0.12. To expose it publicly, a user needs to consult the documentation or similar issue, modify system service configurations, and restart the service to make it listen on the public address 0.0.0.0.
Although the configuration process is not trivial, many users still choose to expose it completely for the convenience of remote access. These users may lack sufficient network security knowledge, and this, combined with Ollama’s characteristic simplicity favored by beginners, has led to the vast number of exposed instances today.
Second, and most critically: Ollama provides no mandatory authentication or risk warnings when configured to listen on 0.0.0.0. This “silent permission” has undoubtedly fueled the proliferation of insecure configurations, leading to a fivefold increase in exposed instances in just eight months.
A final important reason is Ollama’s architectural design. Unlike other frameworks that purely perform inference tasks (e.g., vllm), Ollama runs a system-level daemon in the background. This daemon allows Ollama to respond to API requests at any time, downloading or loading models on-demand. A model is unloaded after about 5 minutes of inactivity to free up resources. This convenient “always-on” design, when exposed to the internet, means an attacker can wake the service at any time to perform arbitrary model operations, multiplying the danger.
To this day, issues requesting native authentication features are still being continuously opened in the official GitHub repository3.
The Risks
Exposing an unprotected Ollama API is equivalent to handing the keys to your server to a stranger. The risks can be categorized into three levels:
Risk 1: Computational Resource Abuse and Financial Loss
This is the most direct consequence. Attackers can unlimitedly call computationally intensive APIs (POST /api/chat, /api/generate, /api/embeddings) to steal your GPU/CPU resources for their own purposes, such as large-scale text generation, data cleansing, or training tasks.
This will not only cause your server to run under continuous high load, slowing down your legitimate services, but could also lead to huge financial losses from high cloud provider bills, effectively resulting in a Denial-of-Service attack4.
Risk 2: Compromised Data and Model Integrity
Attackers can not only use your service but also manage your model assets, arbitrarily compromising your data and model integrity.
- List Models: An attacker can easily obtain a list of all models on your server and their detailed information.
curl http://ip:11434/api/tags

- Download Any Model: An attacker can use the
pullAPI to download any model to your server.
curl http://ip:11434/api/pull -d '{
"model":"qwen3:0.6b"
}'
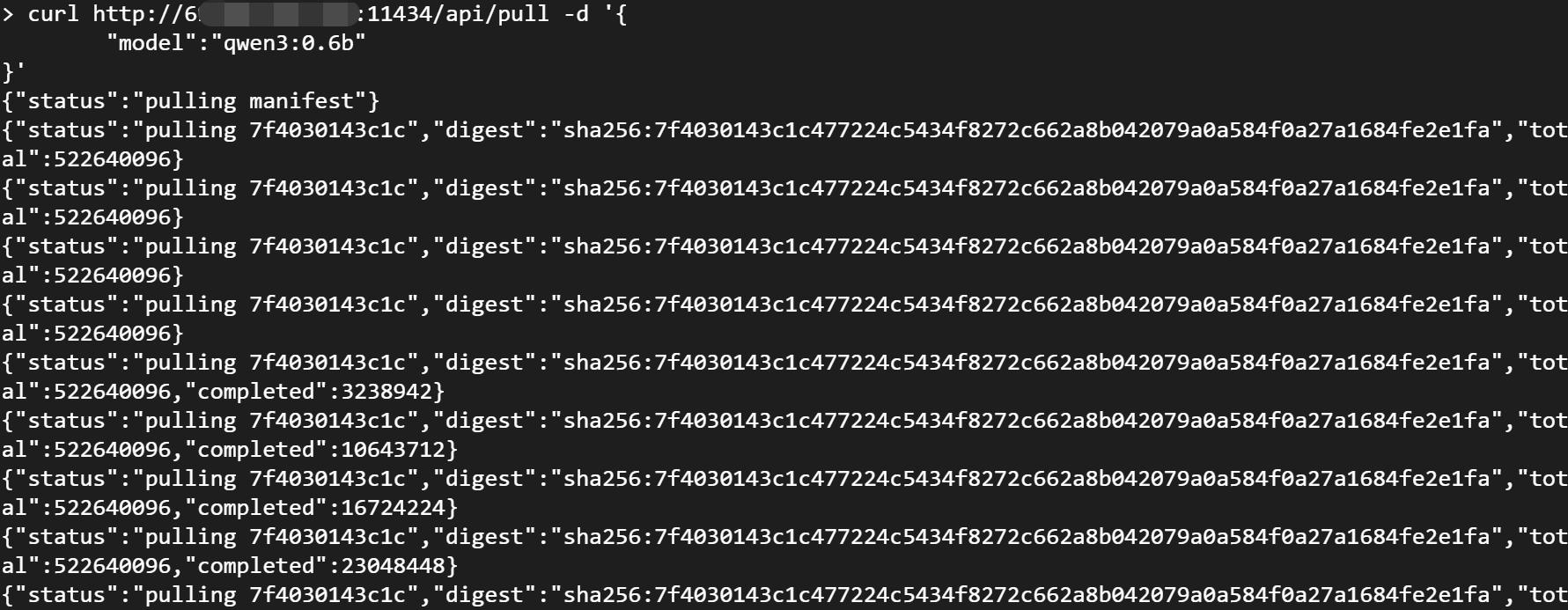
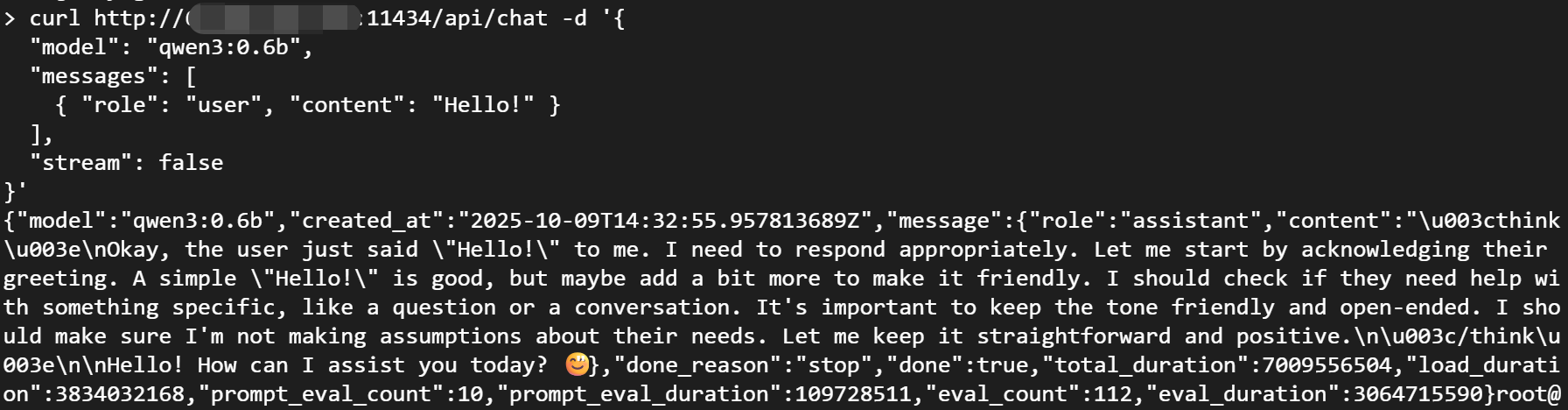
- Run Any Model: An attacker can run any model on your server.
curl http://ip:11434/api/chat -d '{
"model": "qwen3:0.6b",
"messages": [
{ "role": "user", "content": "Hello!" }
],
"stream": false
}'
- Delete Any Model: An attacker can also delete any existing model on your server, including your own private models.
curl -X DELETE http://ip:11434/api/delete -d '{
"name": "qwen3:0.6b"
}'


This is on top of a whole suite of other (and potentially more dangerous) features, such as higher-privilege operations like creating (create), copying (copy), and pushing (push) models, all of which can be done through the Ollama API.
Risk 3: Server Security and System Intrusion
This is the most severe and dangerous consequence. Full API access provides attackers with a potential launchpad to infiltrate your server.
- Storage Exhaustion Attack: An attacker can write a script to repeatedly call the
pullAPI, continuously downloading massive models likellama3:70bto quickly fill up your server’s disk space and cause the system to crash. - Information Leakage: If you are testing or using private models, an attacker can download and steal these model files or obtain their configurations via the
showAPI, leading to the leakage of business or research secrets. - (Potential) Arbitrary Code Execution: The
POST /api/createinterface allows for creating new models via aModelfile. Although Ollama has some sandboxing, an advanced attacker could exploit this feature, possibly combined with vulnerabilities in the model itself, to induce the system to execute malicious commands, ultimately gaining complete control of your server.
How to Protect Yourself
So, how can we protect our Ollama service from being abused by others?
The Golden Rule: Never expose Ollama directly to the public internet without security measures.
The most fundamental and crucial step is to ensure the Ollama service only listens on the loopback address 127.0.0.1, not 0.0.0.0. This guarantees that only the local machine can access it, preventing any possibility of external access from the start.
If you absolutely need remote access, you must deploy one or more of the following solutions:
- Use a Firewall (IP Whitelisting): Configure firewall rules (e.g.,
iptables,ufw) to only allow traffic to port11434from specific, trusted IP addresses (such as your office or home network). - Use a Reverse Proxy with Authentication5: Deploy a reverse proxy server (like Nginx, Caddy) in front of Ollama and configure an authentication layer, such as HTTP Basic Auth or API Keys. All requests must be authenticated before they can reach Ollama.
- Use a VPN or Tunnel: Add your server and client devices to the same Virtual Private Network (e.g., WireGuard, Tailscale). You can then access Ollama via a secure, internal IP address, with all traffic encrypted and never exposed to the public internet.
As users, it is our responsibility to take these measures to protect our digital assets. Hopefully, this article will make more people aware of the severity of this risk and take immediate action.
More importantly, however, we hope that the Ollama team will address this widespread security vulnerability by implementing native authentication features soon, or by providing prominent warnings about the huge risks of public exposure when a user first starts the service, prioritizing user security.
127.0.0.1is the loopback address, allowing access only from the local machine and cannot be probed externally. ↩︎Official authentication for Ollama HTTP/gRPC endpoints (API key / token / mTLS) · Issue #12476 · ollama/ollama ↩︎