LLM API Benchmark MCP Server Tutorial

This article introduces how to configure and use
llm-api-benchmark-mcp-server, a tool that allows LLM Agents to measure LLM API throughput performance under natural language instructions, and details the steps for setting up and conducting concurrent performance tests in Roo Code.
Introduction
When deploying LLMs locally, you might be concerned about whether the throughput performance can meet expectations. Or when calling API interfaces provided by service providers, you might be curious about how LLM providers’ APIs perform under actual concurrent loads, and whether they can meet the demands of most users in multi-user, multi-concurrent scenarios. How to scientifically and accurately evaluate the true performance of these APIs, rather than relying solely on promotional data or instantaneous throughput given by backend tools like vLLM, this tool can help you.
This article mainly introduces the MCP Server, implemented based on this project, which allows your LLM Agent to have a tool that can measure LLM API throughput performance, thereby helping you complete a series of concurrency tests under your natural language instructions.
Project address: https://github.com/Yoosu-L/llm-api-benchmark-mcp-server
Quick Start
This article will use Roo Code as a demonstration to configure the MCP server and perform a simple performance test.
Configure MCP Server
First, find the MCP Server configuration in Roo Code.
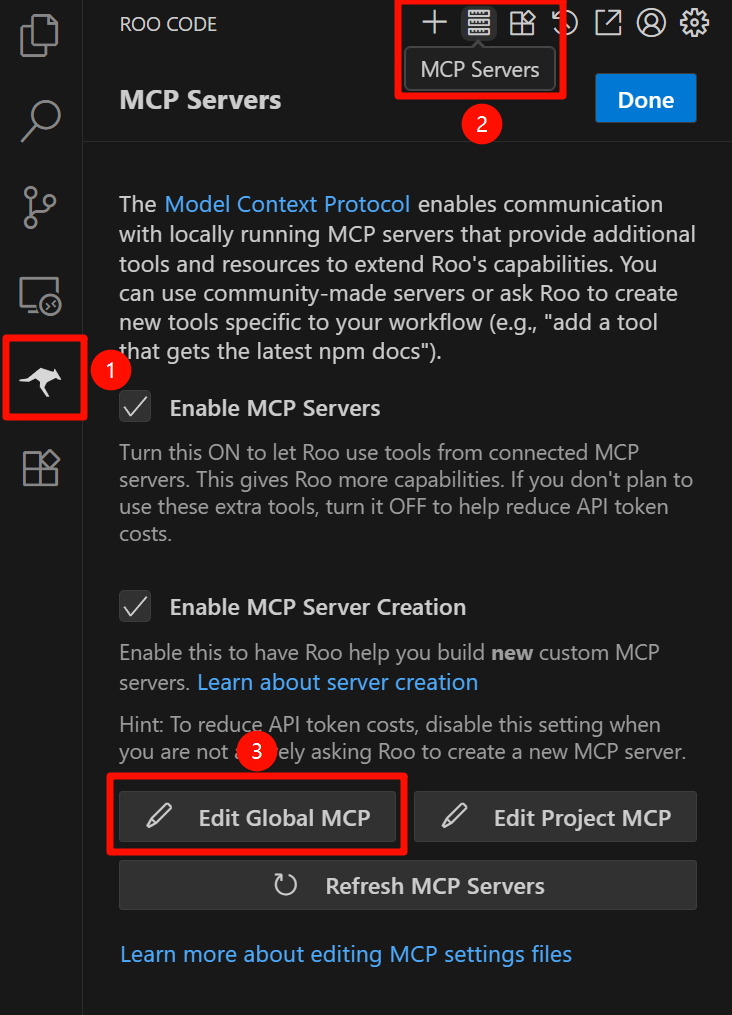
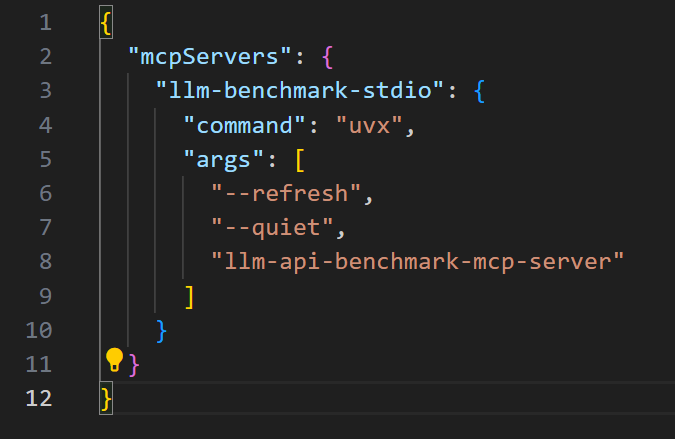
This will open a JSON configuration file. Edit the file:
{
"mcpServers": {
"llm-benchmark-stdio": {
"command": "uvx",
"args": [
"--refresh",
"--quiet",
"llm-api-benchmark-mcp-server"
]
}
}
}
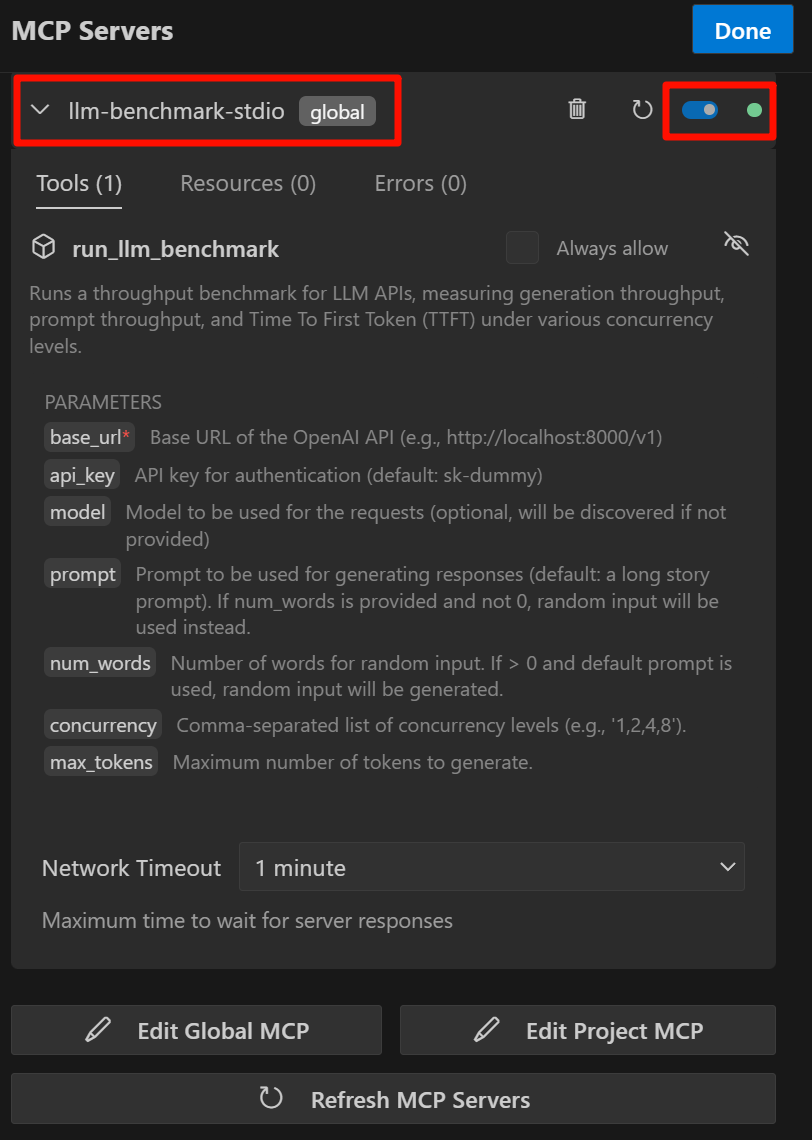
After successful configuration, a new tool will appear on the left MCP Server. A green light indicates successful configuration. If the configuration fails, you can submit relevant information to the Project Issues.
Conversation
Once the tool is enabled, you can start a conversation. Here we use this example prompt:
Please help me perform a LLM api benchmark on this address with concurrency levels of 1 and 2.
https://my-llm-api-service.com/v1, sk-xxx

If the model is good enough, it will prompt whether to allow calling the tool. After clicking allow, the tool will run, and after a while, the model will provide the test results.
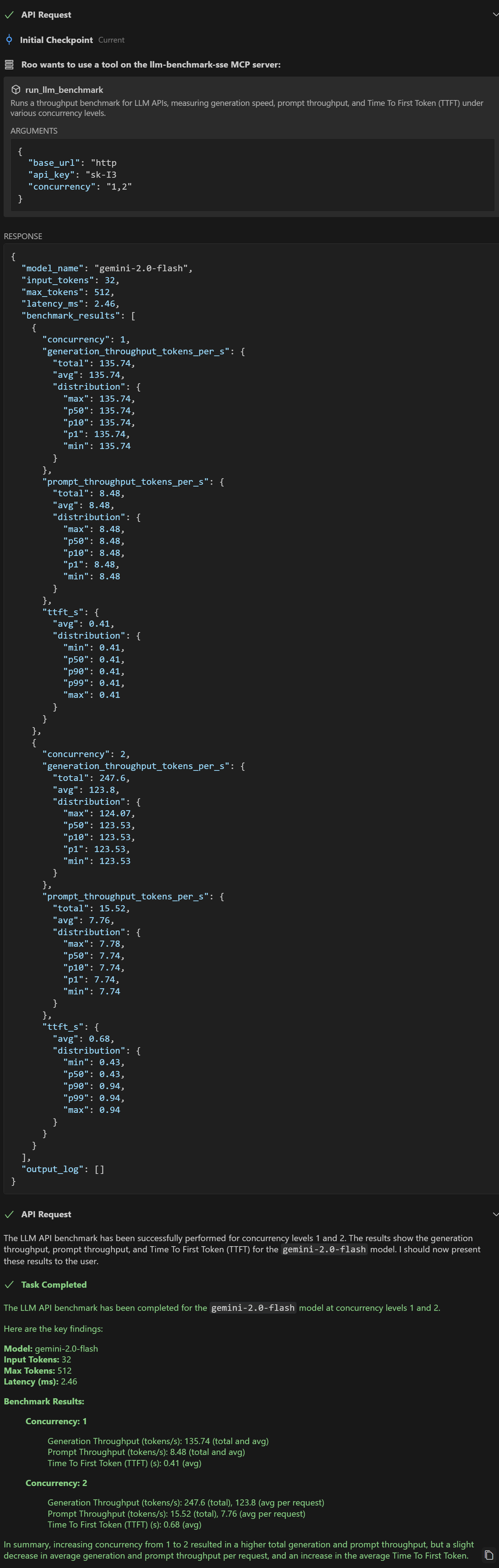
If you want your LLM Agent to further analyze the results, you can continue to ask, but here we are only demonstrating, so we will not proceed with further steps.